
S/4HANA ist im Moment DAS Thema im SAP Bereich sowohl für Unternehmen, die SAP Software verwenden, als auch für SAP-Entwickler und -Berater. Mit der für das Jahr 2025 gesetzten Deadline von SAP für den Auslauf des Supports für die bestehende ERP-Software steht für viele Unternehmen die Migration zu S/4HANA unmittelbar bevor.
Auch für uns ABAP-Entwickler wird sich mit dieser Migration etwas ändern und wir wollen, dass du bestens darauf vorbereitet bist. Deswegen beschäftigen wir uns in diesem ersten Artikel unserer Reihe mit den Grundlagen der HANA Datenbank. In weiteren Artikeln gehen wir dann genauer auf die Veränderungen in der ABAP-Programmierung ein.
S/4HANA und HANA Datenbank
Bereits 2015 erfolgte der Release von S/4HANA und stellt einen Meilenstein in der Evolution der SAP-ERP-Produktlinie dar: von R/2, R/3 über ECC zur vierten Produktgeneration S/4. S/4 nutzt dabei HANA als Datenbanktechnologie. Bei der Migration zu S/4 ist somit die Verwendung von anderen Datenbanken wie Oracle oder IBM nicht mehr möglich wie zuvor mit R/3. Das heißt, dass Unternehmen, die zu dem neuen System migrieren, auch ihre komplette Datenbank migrieren müssen.
Aufbau der HANA Datenbank
Im Gegensatz zu herkömmlichen relationalen Datenbanken, basiert die HANA Datenbank auf der In-Memory-Technologie und kann so kürzere Zugriffszeiten erreichen.
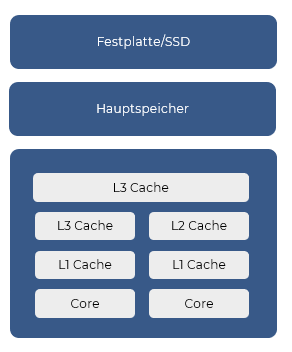
Die Daten werden nicht auf herkömmlichen Speichern wie Festplatten bereitgehalten, sondern in den Hauptspeicher (RAM) geladen. Zeiten für Datenzugriffe verkürzen sich damit auf ein Fünftel.
Natürlich nutzen auch traditionelle Datenbanken den Hauptspeicher. Bei einem Request werden die Daten von der Datenbank in den Hauptspeicher geladen. Wird der gleiche Request nochmals ausgeführt, werden die Daten dann aus dem Hauptspeicher gelesen. Für neue Requests erfolgt erneut ein Datenbankzugriff, was die Performance reduziert. Im Gegensatz dazu werden bei HANA beim ersten Zugriff, z.B. nach einem Systemstart, die Daten einmalig in den Hauptspeicher geladen und darauf zugegriffen.
Bei Datenbanken ohne In-Memory-Technologie stellen die häufigen Zugriffe auf die Festplatte den Performanceengpass dar. Mit der In-Memory-Technologie verschiebt sich dieser Engpass auf den Zugriff auf den Hauptspeicher. Dieser ist nämlich noch immer 4-60 Mal langsamer als der Zugriff auf den Cache.
Das Konzept der In-Memory-Technologie ist nicht neu, galt aber viele Jahre als Nischenprodukt. Lange waren die hohen Kosten, die mit der nötigen Größe des Hauptspeichers zusammenhängen, ein großer Nachteil der In-Memory-Datenbanken. Mittlerweile sind die RAM-Preise deutlich gesunken und somit In-Memory-Datenbanken für Unternehmen eine mögliche Alternative zu herkömmlichen Datenbanken.
Innovationen der In-Memory-Technologie
Datenlayout
Während traditionelle Datenbanken ihre Daten zeilenorientiert halten, kann SAP HANA Daten zusätzlich auch spaltenorientiert ablegen. SAP HANA bietet die Möglichkeit, das Ablageverfahren für jede Tabelle einzeln zu entscheiden. Beide Ansätze haben Vor- und Nachteile aber generell gilt:
| Zeilenorientiert | Spaltenorientiert |
|---|---|
| Schnelle schreibende Zugriffe | Längere schreibende Zugriffe |
| Längeres Lesen der Daten | Schnelleres Lesen der Daten |
Komprimierung
Ziele der Komprimierung sind sowohl eine verkürzte Datenübertragungszeit als auch die Reduzierung des Speicherverbrauchs. Im Fall der In-Memory-Datenbank ist dies besonders wichtig ist, da die Datenbank alle Daten im RAM hält. Die HANA Datenbank verwendet dafür im speziellen die Dictionary-Komprimierung.
Partitionierung
Die Partitionierung kommt zum Einsatz, wenn große Datenmengen vorhanden sind. Sie ermöglicht eine leichtere Verwaltung der Daten. Man unterscheidet zwischen der vertikalen und horizontalen Partitionierung. HANA unterstützt die horizontale Partitionierung.
Auswirkungen auf die Anwendungsentwicklung
Die Entwicklung der Anwendungslogik von ABAP Programmen fand bisher größtenteils in der Applikationsschicht statt. Um von den zuvor beschriebenen Vorteile der HANA Datenbank bestmöglich profitieren zu können, sollte die Anwendungslogik, insbesondere komplexe Kalkulationen, in die Datenbankschicht integriert werden. Damit findet hier ein Paradigmenwechsel statt: Data-to-Code zu Code-to-Data. Die Daten werden nun nicht mehr aus der Datenbank gelesen und dann auf der Applikationsschicht verarbeitet, sondern direkt auf der Datenbank verarbeitet. Dieser Paradigmenwechsel wird auch als Code Pushdown bezeichnet, da der Code in die darunterliegende Datenbankschicht verlagert wird.

Fazit und Ausblick
S/4HANA ist die neue Business Suite von SAP und ist die größte Neuerung der ERP Plattform seit zwei Jahrzehnten. Sie verwendet die HANA Datenbank, die auf der In-Memory-Technologie basiert, die mittlerweile über das Nischendasein hinweg ist.
In den nächsten Beiträgen zeigen wir worauf man in der Programmierung mit der neuen In-Memory-Datenbank achten sollte.
Hast du noch Fragen?
Nutze gerne unsere Kommentarfunktion oder schreib mir direkt an jennifer.schneidmueller@cgi.com
Du programmierst, bist ABAP-interessiert und hast Lust coole Projekte mit uns zu machen? Wir suchen dich! Schau doch mal in unserer Stellenbeschreibung vorbei.